Go-Redis、缓存策略和常见缓存问题
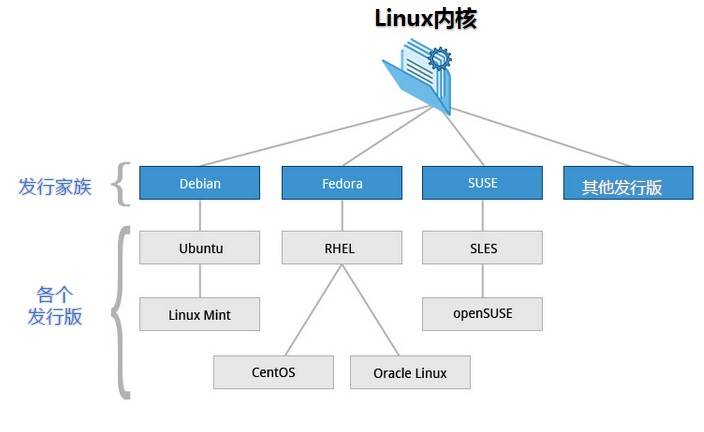
非关系型数据库概述
关系型数据库的优势在于数据的规范性和严格的表格结构,但这也使得它在某些场景下变得不够灵活,尤其是在面对大规模数据、高并发请求和复杂数据结构时,会面临性能瓶颈
与此相对,非关系型数据库摒弃了传统的表格结构,通常具有更灵活的数据存储方式,并且能够根据实际需求进行扩展,尤其适合处理大数据量和快速读写的场景
常见的非关系型数据库包括:Redis、MongoDB等
Redis
意义
如果只使用MySQL之类的关系型数据库,承载不了过大的访问量,过大的访问量会对数据库产生过大压力,导致业务出现问题
在 web 开发里面,为了解决这个问题,我们也引入了缓存的概念。缓存的作用是将数据存储在访问速度更快的内存中,当请求访问这些数据时,直接从内存中读取,避免频繁访问磁盘和数据库,从而大大提高性能。
Redis 是一种高性能的内存数据存储系统,它是一个 NoSQL 数据库,广泛用于缓存场景。通过 Redis,我们可以将数据库中频繁访问的数据缓存起来,从而减少数据库压力,提高响应速度。
基础概念
Redis 有着以下的特性,决定了他天生适合当作分布式缓存中间件使用:
键值对存储:Redis 是一个键值对存储数据库,可以将数据以键值对的形式存储在内存中,支持各种类型的数据结构,如字符串、哈希、列表、集合等。
内存存储:Redis 将数据存储在内存中,这使得它的读写速度极快,远超传统的磁盘数据库。
持久化选项:虽然 Redis 主要作为内存数据库,但它也提供了持久化机制,可以定期将数据保存到磁盘上,以防数据丢失。
高可用性:Redis 支持主从复制、分区、哨兵等机制,能够实现高可用的分布式架构。
数据结构和命令
先连接 redis
1 | redis-cli -h localhost -p 6379 -a <password> |
如果是 docker 部署,需要先进入要 redis 容器里:
1 | docker exec -it redis /bin/bash |
1. String
字符串,最基本的类型,可以存储任何数据,例如文本或数字。命令如下:
SET [key] [value]:添加或修改一个已有的 String 类型的键值对。GET [key]:根据 key 获取 String 类型的 value。MSET [key1 value1] [key2 value2] ...:批量添加多个 String 类型的键值对。MGET [key1] [key2] ...:根据多个 key 获取多个 String 类型的 value。INCR [key]:让一个整型的 key 自增 1。(对应的有 DECR)INCRBY [key] [increment]:让一个整型的 key 自增并指定步长,例如INCRBY num 2让 num 值自增 2。INCRBYFLOAT [key] [increment]:让一个浮点类型的数字自增并指定步长。SETNX [key] [value]或SET [key] [value] NX:添加一个 String 类型的键值对,前提是这个 key 不存在,否则不执行。(分布式锁)SETEX [key] [seconds] [value]或SET [key] EX [value]:添加一个 String 类型的键值对,并且指定有效期(单位:秒)。
缓存如何存储 MySQL 里面的结构化数据呢?
其实很简单,我们 MySQL 里面的一行数据其实对应到 Go 里面就是一个结构体,那么我们可以对这个结构体进行序列化成一个字符串,这样就能当作 json 字符串存储到 string 中
当然这样也有一个弊端,那就是无法灵活修改 string 的成员,下面的数据类型可以帮我们克服这一点。
2. Hash
哈希类型,可以理解为 Go 语言里面的 map,虽然可能会觉得 redis 本身就是一个 kv 数据库,里面还有一个 kv 类型很奇怪,但是这是必要的,一个 key 的 value 就是所谓的 map,可以理解为key里面又存储了多个key的键值对,相较于上面 json 字符串形式存储数据有着一定的优势,那就是对 json 字符串中的单个数据进行修改很不方便,而 hash 类型则可以对单个字段进行 CRUD。
1 | key |
HSET [key] [field1] [value1] [field2] [value2] ...:添加或修改 hash 类型 key 的 field 的值。注:hmset也行,不过已经弃用了.HGET [key] [field]:获取 hash 类型 key 的 field 的值。HMGET [key] [field1] [field2] ...:批量获取多个 field 的值。HGETALL [key]:获取 key 中的所有 field 和 value。HKEYS [key]:获取 key 中的所有 field。HVALS [key]:获取 key 中的所有 value。HINCRBY [key] [field] [increment]:让指定 field 值增加指定步长。HSETNX [key] [field] [value]:添加 field 的值,前提是 field 不存在,否则不执行。
3. List
可以看作是一个双向队列,但是查询速度 O(N),原因在他的底层设计,为了节省内存,所以不支持下标查询,下面是他的命令:
LPUSH [key] [element] ...:向列表左侧插入一个或多个元素。LPOP [key]:移除并返回列表左侧第一个元素,没有则返回 nil。RPUSH [key] [element] ...:向列表右侧插入一个或多个元素。RPOP [key]:移除并返回列表右侧第一个元素。LRANGE [key] [start] [end]:返回指定范围内的所有元素。BLPOP [key] [timeout]:在没有元素时等待指定时间,然后返回列表左侧元素。BRPOP [key] [timeout]:在没有元素时等待指定时间,然后返回列表右侧元素。
4. Set
相当于C++的 unordered_set 或者 Java 的 HashSet,可以用于查看共同好友等,底层使用哈希表实现,
之存储成员,并不是k-v型数据类型,特点是无序,元素不可重复,查找快,支持交集并集这些功能
SADD [key] [member] ...:向 set 中添加一个或多个元素。SREM [key] [member] ...:移除 set 中的指定元素。SCARD [key]:返回 set 中元素的个数。SISMEMBER [key] [member]:判断元素是否存在于 set 中。SMEMBERS [key]:获取 set 中的所有元素。SINTER [key1] [key2] ...:求 key1 与 key2 的交集。SDIFF [key1] [key2] ...:求 key1 与 key2 的差集。SUNION [key1] [key2] ...:求 key1 和 key2 的并集。
5. SortedSet
有序集合,其实就是给上面 Set 的 member 换成 Key-Value 的形式,也就是 Key 为元素,Value 为数值,按照 Value 进行排序,可以实现排行榜之类的功能,常见命令如下:
ZADD [key] [score] [member]:添加或更新元素的 score 值。ZREM [key] [member]:删除元素。ZSCORE [key] [member]:获取元素的 score 值。ZRANK [key] [member]:获取元素的升序排名。ZCARD [key]:获取元素数量。ZCOUNT [key] [min] [max]:统计 score 在指定范围内的元素个数。ZINCRBY [key] [increment] [member]:让元素 score 增加指定值。ZRANGE [key] [min] [max]:按升序获取指定排名范围的元素。ZREVRANGE [key] [min] [max]:按降序获取指定排名范围的元素。ZRANGEBYSCORE [key] [min] [max]:按 score 获取指定范围的元素。ZDIFF、ZINTER、ZUNION:求差集、交集、并集。
其他
其他的数据结构并不算基本的数据结构类型:
- bitmap:底层使用 String 类型实现,其实就是一个位图,每一位只需要 1 bit,占用非常小,很适合用于存储文章阅读,签到状况这些数据。
- Geo:底层使用 SortedSet 实现,用于表示经纬度,如果想要找方圆距离多少的数据,就可以用他,本质是将经纬度对应成分数来打分排行的。
- Stream:算是一个新加入的数据结构,用于实现消息队列,但是本身功能并不多,所以大多数人还是会使用专门的消息队列。
Redis 中键的设计规范
由于Redis中没有表这一结构,于是我们会需要key按照 项目名:业务名:类型:主键id 的方式命名,但并不固定,比如mysql里面的shopping库中的goods表的id为1的数据的 key 可以表示为 shopping:goods:1,而这一个 key 对应的 value 可以是结构体(对象)序列化后的 json 字符串,这里值得一提的是,如果你用的 RDM 的 redis 图形化界面,这样的命名在图形化界面里面会以树的形式出现,显示很清晰,但是 Datagrip 这类软件貌似并不支持这个功能。
go-redis
go 里面既然有 gorm 可以操作 MySQL,那么 go 里面也有一个库可以帮助我们去操作 redis
我们可以通过
1 | go get github.com/redis/go-redis/v9 |
去获取这个包,然后就可以在 go 里面愉快的操作 redis 了
基本命令请看官方教程:API使用教程
示例代码:
1 | package main |
缓存
学习完了Redis基础,接下来该了解Redis如何在项目中作缓存了
缓存基础
我常用的Redis缓存策略通常包含两种类型:写入数据时和读取数据时的操作
写入数据
写入数据时:使用写后删除 + TTL策略
- 直接写入数据库
- 删除缓存,等待下一次读取时再写入缓存
为什么要使用写后删除 + TTL策略?
我们日常使用 Redis 大多是用作缓存,问题来了,我们第一次读取 MySQL 数据的时候,希望将这个数据缓存到 Redis 中,之后的读取就全是使用 Redis 来读取了,那么当有没有 Redis 中缓存的数据与 MySQL 的数据不一致的时候呢?当我们需要写数据的时候,我们肯定需要去写 MySQL 了,那么 Redis 中的数据应该如何处理呢?你们可能觉得很简单,直接修改 Redis 里面的数据不就行了?大多数人最开始做缓存策略可能都是这样做的,但是这样其实还是会导致不一致的问题:
1 | 请求1:写 MySQL |
如果出现上面这种情况,那么就会导致缓存和数据库的数据不一致,在平常自己测试的时候可能很难发现,但是并发度上来了,这种问题就会非常明显。
所以最常见,最简单的做法是写后删除,也就是写完 MySQL 的数据之后,删除 redis 中的数据,缺点是之后又需要重新访问数据库来重建缓存(但是可以用 singleflight 来优化一下)这种情况也有很小的情况会引起数据不一致,如果当时 Redis 没有缓存数据时:
1 | 请求1:读请求,发现 Redis 没有数据,读 MySQL |
虽然也会导致不一致,但是概率很小,所以实际上大多数人都是直接用的写后删除策略 + 合适的 TTL,那么有没有完全避免数据不一致的策略呢?是有的,据我所知:
- 延迟双删:写后先删除一遍,然后过一段时间又删除一遍,当然,实现起来比较复杂,依赖了延迟这段时间,语义上防止比当前写请求还旧的读请求还残留在请求路径上。
- 版本号机制:实现起来比较简单,使用单调增的版本号来防止读旧数据,每次写 MySQL 都将版本号写回到 Redis,这个版本号由于单调增的机制,不会出现旧数据覆盖新数据的情况,所以可以放心写,这样就不用担心旧数据的情况了。
上面还提到了重建缓存是有一定开销的,可以想象一下,在短时间内访问量比较大的时候,如果此时 Redis 中还没有缓存,那么就会有多个请求尝试去重建缓存,这里就会引起不必要的开销,因为实际上我们只需要有一个请求去重建缓存就可以了,剩下的只需要等待,这里就是典型的狗堆效应的问题,最简单的方法就是加锁,分布式场景下就用分布式锁,我之前看见个博客讲的挺好的,现在找不到了,还有个优化策略就是用上述的 singleflight
读取数据
在读取数据时采用以下策略:
- 线尝试直接从缓存中读取
- 缓存未命中,查询数据库
- 写入缓存(分布式锁防止击穿)
缓存击穿、缓存雪崩和缓存穿透
缓存击穿
单个热点key在缓存中过期,此时有大量并发请求访问这个key,所有请求瞬间穿透到数据库,导致数据库压力激增。
解决方案:
- 互斥锁(Mutex Lock)
- 分布式锁(Redis SetNX) (常用)
- singleflight(Go 官方库)
- 热点数据永不过期
缓存雪崩
大量缓存key在同一时间过期,导致大量请求同时穿透到数据库,数据库压力瞬间激增甚至宕机
解决方案:
- 随机过期时间 (常用)
- 分级缓存
- 缓存预热 + 定时刷新
- 服务降级和熔断
缓存穿透
查询一个数据库中不存在的数据,导致每次请求都穿透缓存直接查询数据库。如果被恶意攻击,大量请求不存在的数据,会导致数据库压力过大
解决方案:
- 缓存空值(常用)
- 布隆过滤器(Bloom Filter)
- 参数校验和过滤
总结
| 问题 | 根本原因 | 核心解决方案 | 适用场景 |
|---|---|---|---|
| 缓存击穿 | 热点key失效 | 互斥锁、singleflight、永不过期 | 热点数据、秒杀商品 |
| 缓存雪崩 | 大量key同时失效 | 随机TTL、分级缓存、熔断降级 | 大促活动、批量缓存 |
| 缓存穿透 | 查询不存在数据 | 布隆过滤器、空值缓存、参数校验 | 搜索接口、用户输入 |